

You must log in or # to comment.
No, AI companies don’t “have a PR problem”
They are the problem. It’s in their bones. Harm is their business model. It is not fixable. This is not a case of handing out enough pizza and smiling harder.
If anything, it’s the other way around: we have an AI-company PR problem. Media outlets can’t stop themselves from presenting interviews with CEOs of AI companies as some sort of reliable source for how incredible AI really is if we would only spend more money locking ourselves into AI-driven workflows.
TL;DR the umbrella-selling weatherman keeps predicting that rain is on the way
AI is literally just legalized theft of other people’s work. It won’t credit them to any capacity.
Also, whilst it is adding some productivity, it’s also being used by absolute idiots who have no idea what they’re doing spreading bad info and causing other people more work.
Every idiot is typing everything into chatgpt, getting a bad answer which is obvious to anyone half trained and then promoting it like it’s correct just because AI said it
whilst it is adding some productivity
Is it though? Like what’s the evidence of that? If it just feels like it must be true, I have some bad news about that:
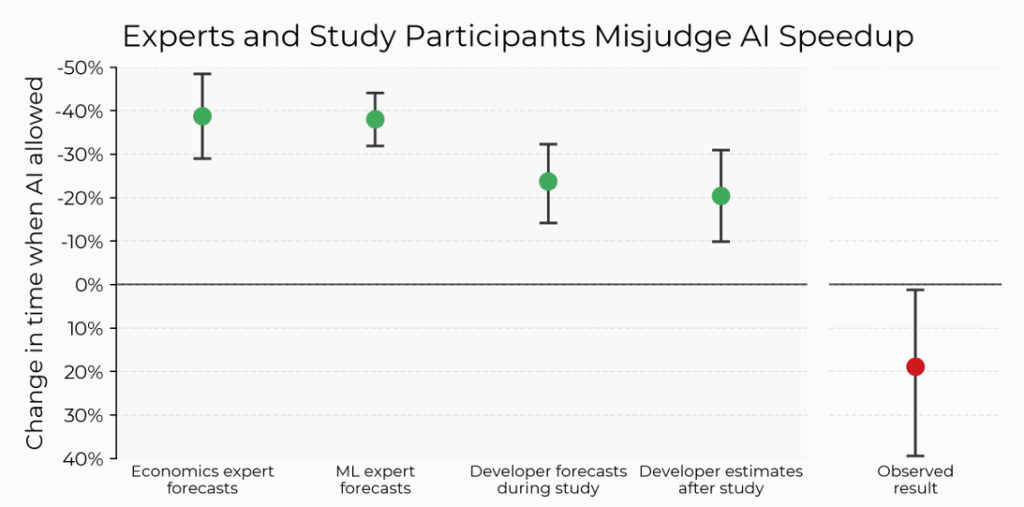
The most interesting part of this isn’t that it slowed them down when they expected to be faster, it’s that even after it slowed them down, they couldn’t tell and were fooled that they had been faster.
Look at the graph, especially the last two lines:
https://cdn.arstechnica.net/wp-content/uploads/2025/07/aicodingchart-1024x507.png
My theory about this is that LLMs were tasked with giving useful output, but they couldn’t do that, because they have no fidelity, so instead they found a shortcut, which was to trick people into thinking they were being useful. They found the same loophole that conmen have used for millenia, and automated it. It’s the AI alignment problem, only for some reason people aren’t talking about it, maybe because they don’t want to believe that we’re this easily manipulated.
There’s no reason to believe LLMs have gotten any better at actually doing useful work in the meantime in the absence of any objective measure of it. I think the best explanation for their “improvement” is that they have simply gotten better at fooling us.
That’s from almost a year ago. I’m sure it was accurate at the time, but LLMs got a lot more useful around December 2025 or so. Tooling for them has also evolved a lot since then.
Data or you’re just getting fooled better.
Unfortunately, I don’t know what data I can share, so I’ll err on the side of caution and share none 🙂. But I suppose I can share a little more general insight:
Modern “agentic” (yeah I’m tired of that word too) techniques, patterns, and tools, paired with modern LLMs allow for much more autonomy than what was available a year ago.
Are agents faster than skilled engineers per task? No, not in most cases. But they allow engineers to scale horizontally, knocking out many tasks in parallel.
That’s the performance gain: Foster autonomy for horizontal scaling. Build/optimize projects’
AGENTS.mdandSKILL.mdfiles[1].Agents can work for some long runs (some engineers even run them overnight), given a safe environment/project with guardrails — mostly the same guardrails that human engineers have had for years: Statically typed languages, TDD, good test coverage, code reviews (both agents and human[2]), CI pipelines, etc.
They still need human engineers to operate them; the workflow is just different now, and there’s a learning curve for it.
Whether we like it or not (personally, I miss the old days), this is just how it is now. We have not even reached the peak yet. This is the least autonomous that agents will ever be.
The bigger the repo, the more important this probably is. Structure them so they don’t bloat the context windows with unnecessary info. ↩︎
I usually wait for the AI agent review cycles to settle first — no need to spend human engineering time on potential slop that will probably get fixed autonomously. ↩︎
You’ve been given evidence that people cannot trust their own perceptions of what these agents do, and you replied by telling a bunch of stories about why you think you personally can trust your perceptions. My 12-year-old did the same thing when I tried to explain this to them.
Engineers being spread thinner to manage a wider number of tasks whilst reviewing shitty LLM noise that they didn’t write is inevitably going to make horrible code that’s impossible to maintain and will cost massive amounts of time and resources in the long run.
And the idea that it allows more things to be done is just a bunch of “it makes you faster” assessments in a trenchcoat.
Agentic or not, they still have zero fidelity. Fidelity can only come from an internal model of reality that the network is comparing its inputs to, and I’m pretty sure you don’t get that without AGI.
The data we have till this point shows that they don’t help, they only create an illusion of helping. And until you can show that that has fundamentally changed, then you have to assume that the improvements you’re seeing are just improved illusions.
You’ve been given evidence that people cannot trust their own perceptions of what these agents do, and you replied by telling a bunch of stories about why you think you personally can trust your perceptions. My 12-year-old did the same thing when I tried to explain this to them.
You asked for data. I (probably) can’t give you the data, so I gave you what I could: a few things gleaned from both objective data (collected from a significant number of engineers) and my own anecdotal experience. You are free to disregard it, and I wouldn’t even blame you. There are lots of fools on the internet, and there’s a decent chance that I’m just another one 🙂.
Engineers being spread thinner to manage a wider number of tasks whilst reviewing shitty LLM noise that they didn’t write is inevitably going to make horrible code that’s impossible to maintain and will cost massive amounts of time and resources in the long run.
This was true a year ago. Even like seven months ago. Hell, even three months ago, I would have agreed with you a LOT more than I do today – mostly because I was just forced learn these things more in-depth quite recently. “Shitty LLM noise” is a very early part of the learning curve. In a way, it’s similar to “Hello world.” Discard it and figure out how get more useful results.
In many companies that have adopted AI, engineers are still responsible for their code. Any slop in the codebase is the fault of the engineer that introduced it (and the engineer[s] that reviewed it), regardless of whether it’s hand-written or generated. So far, I have not seen anyone merge unmaintainable, “shitty LLM noise” into enterprise codebases – that would be very risky. (It probably happens in other places like Microsoft, I just haven’t seen it myself. It would be unacceptable.)
Anyway, you’ll see all this eventually, when some data gets published. I’d gain nothing by convincing anyone of this, so I won’t try 🙂.
This is just a statement of faith in your ability to judge these things accurately. Nowhere in here do I see any evidence that you’ve even considered that the reason you’ve changed your attitude towards the tech is that it’s just gotten so good at fooling people that it’s finally got you.
You don’t gain much from trying to convince me, but you could gain a lot from being more sceptical. People invented science to address the fact that our intuitive understanding doesn’t always reflect reality.
Science and the collection of objective data stops us from doing this:

There are a bunch of things that our brains just don’t understand intuitively, so we need to check our intuition against measurement. There’s no shame in that, but when it’s pointed out, then you have a chance to check yourself.
But you don’t seem to understand that. When you say:
Anyway, you’ll see all this eventually, when some data gets published.
you are demonstrating that you are the perfect mark for this stuff, because you are not reflecting on your own thought process to see where it might be failing you.
The plague of work chats now:
Here’s what ChatGPT/copilot had to say:
People can ask for themselves, you answering that way adds no value. Just say you don’t know.
In group chats, keep your mouth shut and let people that actually know answer. Don’t drown out the actual expert answers.
And holy hell the ones that will die on the hill that they are right because chatgpt agreed with them even when they are totally wrong…

Isn’t archive.is blocked because they injected ddos scripts in their visitors browsers?
Yes and modified articles without letting users know.
I’ve never heard of either of these things. Do you have sources?
Wikipedia has since banned them as a source.
That’s nuts. Thanks for the source! I hadn’t heard about that
Hard disagree. We aren’t hating AI and it’s users nearly enough.
Not a fan of the framing of the question, but…
“Some version of AI is inevitable” said the CEO of an AI company
… This insight was very novel, thank you Axios
It’s hilarious to me that news companies keep interviewing AI companies to ask them if they think AI is all hype. What kind of answer do they expect?
“Yeah, this is just smoke and mirrors, and I’m just trying to make a ton of money before the bubble pops.” Bruh, no CEO is gonna be honest about that.
We will accept spell checkers.
Which isn’t wrong per se, but maybe they don’t realize (or don’t want to) that we’d prefer useful AI, not the “burn the world and turn it into money” kind.
It’s a major political issue. While “everything Israel ever wants should be US priority” has solid US consensus, “Skynet for US oligarchist privatized profits to ensure compliance with Zionist supremacism, and not just subjugation of Americans through oligarchist driven unemployment but subjugation to supporting skynet” or China wins is about even with political establishment support for Israel supremacy.
Government operations buying AI services is integral to “need to beat China”, and “evil operations”, and circular financing back to politicians meant to maximize this, is by design.
Well, yeah, AI is mostly garbage. Fuck it. Fuck the people pushing it.
Garbage is a harsh word. Technically fascinating and surely has its applications. “Talking” with bots surely isn’t a good one. Using it for important stuff? Surely ain’t it either.
Letting it sum up some 5838292 pages of a boring contract to get a slight oversight? Helpful. Relying on it? Dumb.
Getting some translation that can make sense? Helpful. Betting your life on it? Dumb.
Letting then quickly throw a prototype at you in 2 mins that would’ve taken you 2hours? Helpful. Just deploy it to 100 machines without manually checking? Dumb.
Don’t blame the tool, blame the user 😁
Don’t blame the tool, blame the user 😁
I compare it to snapshot tests a lot. They’re similarly constrained by “good if used wisely” but most people don’t do that. It’s easier to use them extensively. That’s just how people are. They do the easy thing
Hehe, yeah sure. Easy is awesome. I see why people use those bots for everything. You can get shoulder-pats for even the dumbest shit opinion you throw at them. And “evidence” too. I would put a smiley here because it sounds funny and absurd to me, but sadly it ain’t funny.
People shouldn’t be allowed to use “AI” until they got a license for it. Like cars.
Just ask who got the gains in the last industrial revolution and who got to live in the slums, and how they plan to do things differently now.
Removed by mod





{kind=link}